

We develop explainable and reliable end-to-end autonomous systems that transcend the limits of simple imitation by integrating human-centric reasoning. Our research focuses on high-fidelity 3D occupancy prediction and multimodal sensor fusion to ensure safe navigation in dense, complex urban environments. By pioneering "advisable" learning, we empower vehicles to interpret high-level human guidance and provide transparent textual rationales for their driving decisions.
We bridge the gap between high-level linguistic reasoning and low-level physical control to create failure-resilient embodied agents. Our work leverages Chain-of-Thought (CoT) processing and structured scene graphs to enable robots to perform long-horizon planning and proactive self-correction in dynamic settings. We aim to build intelligent digital and physical beings that can naturally communicate, assist, and interact with humans through a deep understanding of the 3D world.

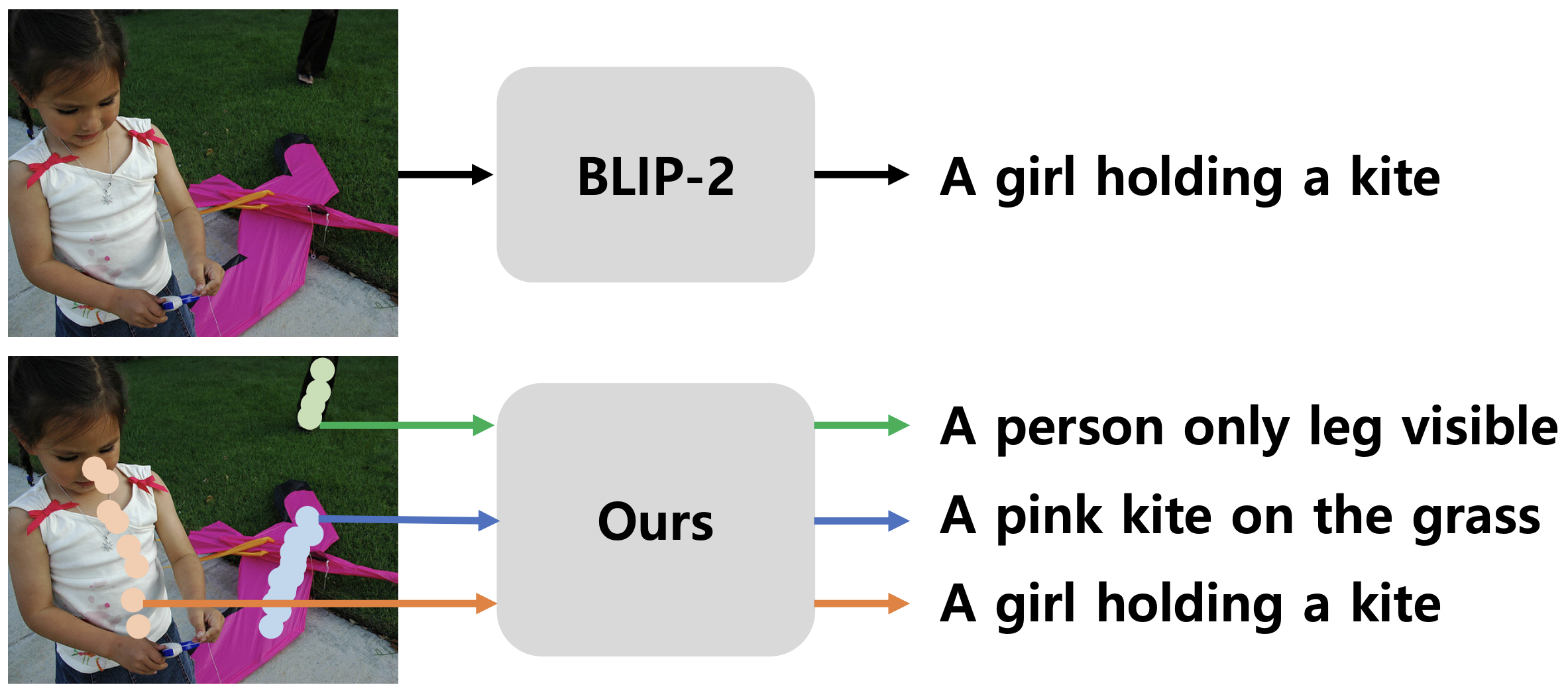
We advance the frontier of multimodal foundation models by prioritizing factuality, label-efficiency, and trustworthiness. Our research develops robust mechanisms for mitigating hallucinations in large vision-language models and introduces innovative techniques for machine unlearning and negation awareness. By focusing on weakly supervised learning and parameter-efficient adaptation, we ensure that large-scale AI remains sustainable, safe, and ethically aligned for deployment in high-stakes domains.


Vision & AI Lab
Dept. of Computer Science & Engineering
College of Informatics
Korea University
Woojung Hall of Informatics #602
145 Anam-ro, Seongbuk-gu, Seoul, Korea